

The anticipation for preseason ratings is an interesting thing. People like to talk about the projections, poke holes in them, figure out why their team is underrated. But obviously, no team is bound by the shackles of its preseason forecast. Oregon State is predicted to finish last in the Pac-12 by most robots (and humans, for that matter), but nothing is stopping the Beavers from running the table in conference play.
I guess if you want to get technical, a lack of talent might be a significant obstacle for them. But the robots will not be. If Oregon State wins its first four conference games, the robots are not going to hire Shane Stant to visit the Beavers’ locker room. In that sense, the ratings are irrelevant.
However, there is good reason to have some interest in preseason projections. For most programs, the forecasts are a reasonable estimate of what neighborhood a team will reside in this season. There were four systems that made comprehensive preseason forecasts last season. Here’s the average error in forecasting regular-season conference wins for each of them…
Dan Hanner 2.09 TeamRankings 2.11 Kenpom 2.14 Matchup-Zone 2.15 Consensus 2.04
The consensus is the average of the four forecasts and it’s heartening to know that for the second consecutive season it beats any individual model. The Hanner and Matchup-Zone models are heavily player-based, while TeamRankings is less so, and mine is even more handicapped in terms of personnel awareness. Still, all of the knowledge combined would make for a better model, at least in terms of predicting conference record.
Here’s another way to look at it. How often was each system off in terms of wins?
Error KP TR DH MZ 9 0 0 1 0 8 1 0 0 0 7 3 3 4 5 6 4 5 6 10 5 18 23 17 18 4 49 41 40 35 3 55 55 61 60 2 75 77 73 77 1 96 91 85 92 0 49 55 63 53
My system had fewer bullseyes, but in its defense it also had fewer big misses. It tends to be more conservative than its counterparts. Regardless of which system you prefer, about 63 percent of all teams had an error of two games or fewer. (The systems are nearly identical in this sense. TeamRankings had 223 teams with an error of two games or less, Matchup-zone had 222, Hanner had 221, and I had 220.)
So each of the forecasting systems probably gets your team correct in terms of its rough location in the conference standings. You may make certain inferences about the lack of true parity in college basketball given this level of predictability. I’m not here to poo-poo parity, but certain things about this sport are reasonably predictable. However, there are always a few teams that make the predictions look silly.
One of the benefits of a reasonable prediction model is that you get a better starting point for identifying surprises. Here were the biggest errors from last season:
Predicted conference wins, consensus vs. actual
Team Consensus Actual Diff Fairfield 11.00 4 -7.00 American 6.25 13 +6.75 Nebraska 4.50 11 +6.50 Niagara 9.25 3 +6.25 Villanova 10.00 16 +6.00 Southern Utah 7.00 1 -6.00 TAMU-CC 8.00 14 +6.00 Georgia 6.25 12 +5.75 Utah Valley 7.25 13 +5.75 Oklahoma St. 13.50 8 -5.50
One limit of this evaluation method is that we are talking about the predictions for each team relative to its conference and not about a team’s relationship to the larger college hoops universe. One way to look at the big picture is to take the teams at the top of the rankings and see how successful they were. Here’s a compilation of each system, along with the AP poll, and the NCAA tournament seed that each team received.
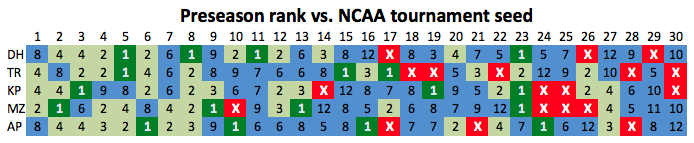
I don’t believe there’s an established scoring system for grading these things, but the one I use indicates it’s Hanner by a hair over the AP.
Finally, I’ll make my annual plea for anyone doing this sort of work to send me their output of forecasted conference wins. I’ll track the error and post the results at this time next season.